First graph in ggplot
Getting the data
We can, of course, download the data set we want and then use tools such as readr (if it is a csv file) to import the data. But that misses out on quite a powerful way of grabbing information. Many organisations have set up a way of asking questions directly to their database - think about it like a machine-to-machine conversation.
This is called an API (Application Programming Interface), and there are lots of them about. So, a basic understanding of how to get that information into an R dataframe for analysis is really important.
And just for an added bonus, we’re going to build on the concepts from the pivot table session to add in a graph using ggplot2 (again a tidyverse tool).
Tools for the job
We’ll be using httr to work with our APIs - it makes it much easier to construct a question. I’ve tried using the paste() function to do this in the past and didn’t find it easy, httr is much nicer in comparison.
The response from our questions is often in the form of either JSON or XML. The documentation for the API will tell you about what form it is in and that will tell us what tools we need to deal with the particular formats.
We’ll be using an API from the data.police site, which returns data from queries as JSON - we’ll need the jsonlite package to help us with that.
The final package is the tidyverse to allow us to do some data changes, in a similar way to what we’ve done before and to generate the chart we are going to make at the end.
So, usual rules create an R script file in RStudio and we can get working.
library(httr)
library(jsonlite)
library(tidyverse)
What are we looking for?
The first step is to look at what kind of crimes we can investigate. The documentation for the data.police site’s API gives this examples of the different API queries that are available. You can just copy and paste one of the examples into a web browser to see what is going on. I’ve picked the crime categories API page - which shows an example that looks like this - https://data.police.uk/api/crime-categories?date=2020-03. Copy and paste that into a web browser to get a JSON view of the data.
I’ve had a look at the webpage and inspired by what I’ve seen in the news recently, I’m going to look at car crime around the main hospital in Cardiff. You could swap any category in this.
Building our query web address
We’ll be looking at street level crimes, this call is built is in three parts:
- The basic structure
https://data.police.uk/api/crimes-street/ - The crime type
vehicle-crime - The query
lat= long= date=
I’ll go onto Google Maps in Chrome and search for University Hospital of Wales - the hospital mentioned in the story I read. If you right click on the point you searched for in the browser window, you can pick What's here? and you’ll get a little pop-up with the latitude and longitude on the bottom. Copy that over to your script.
We’re going to store the first part of the address in an object called url. I’ve copied an example from the documentation but changed it from the usual all-crimes? to vehicle-crime?.
We’ll wrap the web address in double quotes and use the <- assign symbol.
url <- "https://data.police.uk/api/crimes-street/vehicle-crime?"
We’ll now start structuring our request to the data.police server. We’ll be using GET() from httr - it does what it says. We’ll tell it what the url is that we are using and then give it a list() with our query elements inside it. Have a play with the dates and see what is going on - you may get error messages. If so, Google them and find out what they mean.
An important point in checking your code is watching out for how many brackets you have. This is a real source of broken code for beginners, so watch out for it. This section below has two opening brackets - one for GET and one for list, so we must have matching closing brackets. If it isn’t matched the code will not run.
In mock structure it looks like this - our_stored_call <- GET(base_address, query = list(some queries, separated by commas)). I’ve hit return at points below to make it easier to read, it will be treated as one line of code like this.
api_call <- GET(url = url,
query = list(
lat = 51.50724,
lng = -3.190278,
date = "2020-02")
)
The key thing to do when you make a call to an API is to check what has happened - they all have a status code built into the return. We can access this by running one line of code - api_call$status_code.
It will return a number - 200 means all is well, numbers in the 400s usually mean you haven’t structured your call properly and 500s means their API isn’t working.
We’ve got a 200 - all is well.
api_call$status_code
## [1] 200
The way JSON is structured means there is a header with lots of background information (metadata) and content - which is what we want. We’ll use jsonlite’s content() function and specify how we want it back.
response <- content(api_call, as = "text", encoding = "UTF-8")
I wouldn’t normally use head() to look at the top of this kind of object but, let’s do it here to see what we get back. You can call head() on many types of data object in R to see what you’ve got at the head (top) of it. You can even tell it how many to look at by adding an n = * argument eg head(object, n = 6).
head(response)
## [1] "[{\"category\":\"vehicle-crime\",\"location_type\":\"Force\",\"location\":{\"latitude\":\"51.510986\",\"street\":{\"id\":1082838,\"name\":\"On or near Heol Wernlas\"},\"longitude\":\"-3.207382\"},\"context\":\"\",\"outcome_status\":{\"category\":\"Under investigation\",\"date\":\"2020-02\"},\"persistent_id\":\"cb7458646b734199c1728e7ba2b0cc375cb792a1d181092c30e3a8a217838c32\",\"id\":81238108,\"location_subtype\":\"\",\"month\":\"2020-02\"},{\"category\":\"vehicle-crime\",\"location_type\":\"Force\",\"location\":{\"latitude\":\"51.504594\",\"street\":{\"id\":1083004,\"name\":\"On or near Dovedale Close\"},\"longitude\":\"-3.169997\"},\"context\":\"\",\"outcome_status\":{\"category\":\"Investigation complete; no suspect identified\",\"date\":\"2020-03\"},\"persistent_id\":\"1b5a72e887633314e5f0f570e97a8112bc99781745db1b3c54f3a0815117628f\",\"id\":81238172,\"location_subtype\":\"\",\"month\":\"2020-02\"},{\"category\":\"vehicle-crime\",\"location_type\":\"Force\",\"location\":{\"latitude\":\"51.497118\",\"street\":{\"id\":1081632,\"name\":\"On or near Petrol Station\"},\"longitude\":\"-3.192711\"},\"context\":\"\",\"outcome_status\":{\"category\":\"Investigation complete; no suspect identified\",\"date\":\"2020-03\"},\"persistent_id\":\"b66c1dcefad0ced8cffde6924ae86bf36df004c84c48389c15db6e44a99baff6\",\"id\":81238305,\"location_subtype\":\"\",\"month\":\"2020-02\"},{\"category\":\"vehicle-crime\",\"location_type\":\"Force\",\"location\":{\"latitude\":\"51.515486\",\"street\":{\"id\":1083744,\"name\":\"On or near Heath Park Lane\"},\"longitude\":\"-3.182295\"},\"context\":\"\",\"outcome_status\":{\"category\":\"Investigation complete; no suspect identified\",\"date\":\"2020-02\"},\"persistent_id\":\"4d918317cd772b800243401b2deba7a91f11a86f9da0080d6dd9d84d4b9ef83f\",\"id\":81239441,\"location_subtype\":\"\",\"month\":\"2020-02\"},{\"category\":\"vehicle-crime\",\"location_type\":\"Force\",\"location\":{\"latitude\":\"51.497118\",\"street\":{\"id\":1081632,\"name\":\"On or near Petrol Station\"},\"longitude\":\"-3.192711\"},\"context\":\"\",\"outcome_status\":{\"category\":\"Under investigation\",\"date\":\"2020-02\"},\"persistent_id\":\"2b2163a342579acc4b7d457b1a270a26acb7cc116ff948c8e35628bddd4e005a\",\"id\":81238244,\"location_subtype\":\"\",\"month\":\"2020-02\"},{\"category\":\"vehicle-crime\",\"location_type\":\"Force\",\"location\":{\"latitude\":\"51.497118\",\"street\":{\"id\":1081632,\"name\":\"On or near Petrol Station\"},\"longitude\":\"-3.192711\"},\"context\":\"\",\"outcome_status\":{\"category\":\"Investigation complete; no suspect identified\",\"date\":\"2020-02\"},\"persistent_id\":\"3df4e80f4bcd590c1760c5df0be5755ec90d7acb5711e23ecc1b07c4d263ba6b\",\"id\":81239576,\"location_subtype\":\"\",\"month\":\"2020-02\"},{\"category\":\"vehicle-crime\",\"location_type\":\"Force\",\"location\":{\"latitude\":\"51.496468\",\"street\":{\"id\":1081601,\"name\":\"On or near Rhygoes Street\"},\"longitude\":\"-3.184972\"},\"context\":\"\",\"outcome_status\":{\"category\":\"Investigation complete; no suspect identified\",\"date\":\"2020-02\"},\"persistent_id\":\"e13bff04cc19a9f8331d4e1cff06ec4d132ca636e728f465f802aa8a187835ae\",\"id\":81239620,\"location_subtype\":\"\",\"month\":\"2020-02\"},{\"category\":\"vehicle-crime\",\"location_type\":\"Force\",\"location\":{\"latitude\":\"51.496485\",\"street\":{\"id\":1081626,\"name\":\"On or near Brithdir Street\"},\"longitude\":\"-3.184180\"},\"context\":\"\",\"outcome_status\":{\"category\":\"Investigation complete; no suspect identified\",\"date\":\"2020-02\"},\"persistent_id\":\"f9443b6ebbb08eb279883f4cfd79947c988edccda3b2615dcc5d30e698eeb496\",\"id\":81238098,\"location_subtype\":\"\",\"month\":\"2020-02\"},{\"category\":\"vehicle-crime\",\"location_type\":\"Force\",\"location\":{\"latitude\":\"51.495872\",\"street\":{\"id\":1081618,\"name\":\"On or near Gelligaer Gardens\"},\"longitude\":\"-3.187881\"},\"context\":\"\",\"outcome_status\":{\"category\":\"Investigation complete; no suspect identified\",\"date\":\"2020-02\"},\"persistent_id\":\"a0e5ca870b8a6c756b28529e7e6554ae499810a12ccf0e3e33be946fd48eb18c\",\"id\":81238168,\"location_subtype\":\"\",\"month\":\"2020-02\"}]"
That’s great, notice how each individual reported crime is wrapped in {}? We can get that out of JSON and into a dataframe like this:
We’ll use fromJSON() and tell it what object to work on, and we want to flatten it. We can use a pipe %>% to add another command and this one will be to set it up as a data.frame().
vehicle_crimes <- fromJSON(response, flatten = TRUE) %>%
data.frame()
# let's have a look at the structure of the dataframe
str(vehicle_crimes)
## 'data.frame': 9 obs. of 13 variables:
## $ category : chr "vehicle-crime" "vehicle-crime" "vehicle-crime" "vehicle-crime" ...
## $ location_type : chr "Force" "Force" "Force" "Force" ...
## $ context : chr "" "" "" "" ...
## $ persistent_id : chr "cb7458646b734199c1728e7ba2b0cc375cb792a1d181092c30e3a8a217838c32" "1b5a72e887633314e5f0f570e97a8112bc99781745db1b3c54f3a0815117628f" "b66c1dcefad0ced8cffde6924ae86bf36df004c84c48389c15db6e44a99baff6" "4d918317cd772b800243401b2deba7a91f11a86f9da0080d6dd9d84d4b9ef83f" ...
## $ id : int 81238108 81238172 81238305 81239441 81238244 81239576 81239620 81238098 81238168
## $ location_subtype : chr "" "" "" "" ...
## $ month : chr "2020-02" "2020-02" "2020-02" "2020-02" ...
## $ location.latitude : chr "51.510986" "51.504594" "51.497118" "51.515486" ...
## $ location.longitude : chr "-3.207382" "-3.169997" "-3.192711" "-3.182295" ...
## $ location.street.id : int 1082838 1083004 1081632 1083744 1081632 1081632 1081601 1081626 1081618
## $ location.street.name : chr "On or near Heol Wernlas" "On or near Dovedale Close" "On or near Petrol Station" "On or near Heath Park Lane" ...
## $ outcome_status.category: chr "Under investigation" "Investigation complete; no suspect identified" "Investigation complete; no suspect identified" "Investigation complete; no suspect identified" ...
## $ outcome_status.date : chr "2020-02" "2020-03" "2020-03" "2020-02" ...
We can now start looking at what we’ve got going on in our dataset. First off, we’re going to get rid of some of the columns we don’t need. We’ll be overwriting the data by storing it in the same dataframe. dplyr’s select() allows us to pick what we want and give it a new name into the bargain - we used rename() last time. Both work.
I tend to keep IDs for matching with things later, to check crime outcomes - but today for one time only we’ll get rid of it.
vehicle_crimes <- select(vehicle_crimes,
month, category,
location = location.street.name,
long = location.longitude,
lat = location.latitude,
outcome = outcome_status.category)
Great, so we’ll group the crimes to see what is happening - we could do this on any one of the columns but for now we’ll do it on outcome.
We’ll use mutate() and recode() to simplify one of the descriptions (old = new), then we’ll z to get the unique objects and summarise() by counting (n()) the number of times it occurs before we arrange() in descending (desc()) order.
outcomes <- vehicle_crimes %>%
mutate(outcome = recode(outcome,
"Investigation complete; no suspect identified" = "No suspect identified")) %>%
group_by(outcome) %>%
summarise(outcome_count = n()) %>%
arrange(desc(outcome_count))
A really simple chart
One of the tools I use a lot, and get all of my students to use, is the FT’s Visual Vocabulary which was designed to help the FT’s team pick the right kind of tool for the job. I’ll be posting more about data visualisation soon.
I’m going to build a really simple column chart, using ggplot2. ggplot() has a + symbol which is like the pipe from dplyr and means AND THEN. So, we tell ggplot() what dataframe to work on, and what data to work on for the axes (aes()) and then what type of chart to work with.
ggplot(outcomes, aes(x = outcome, y = outcome_count)) +
geom_col()
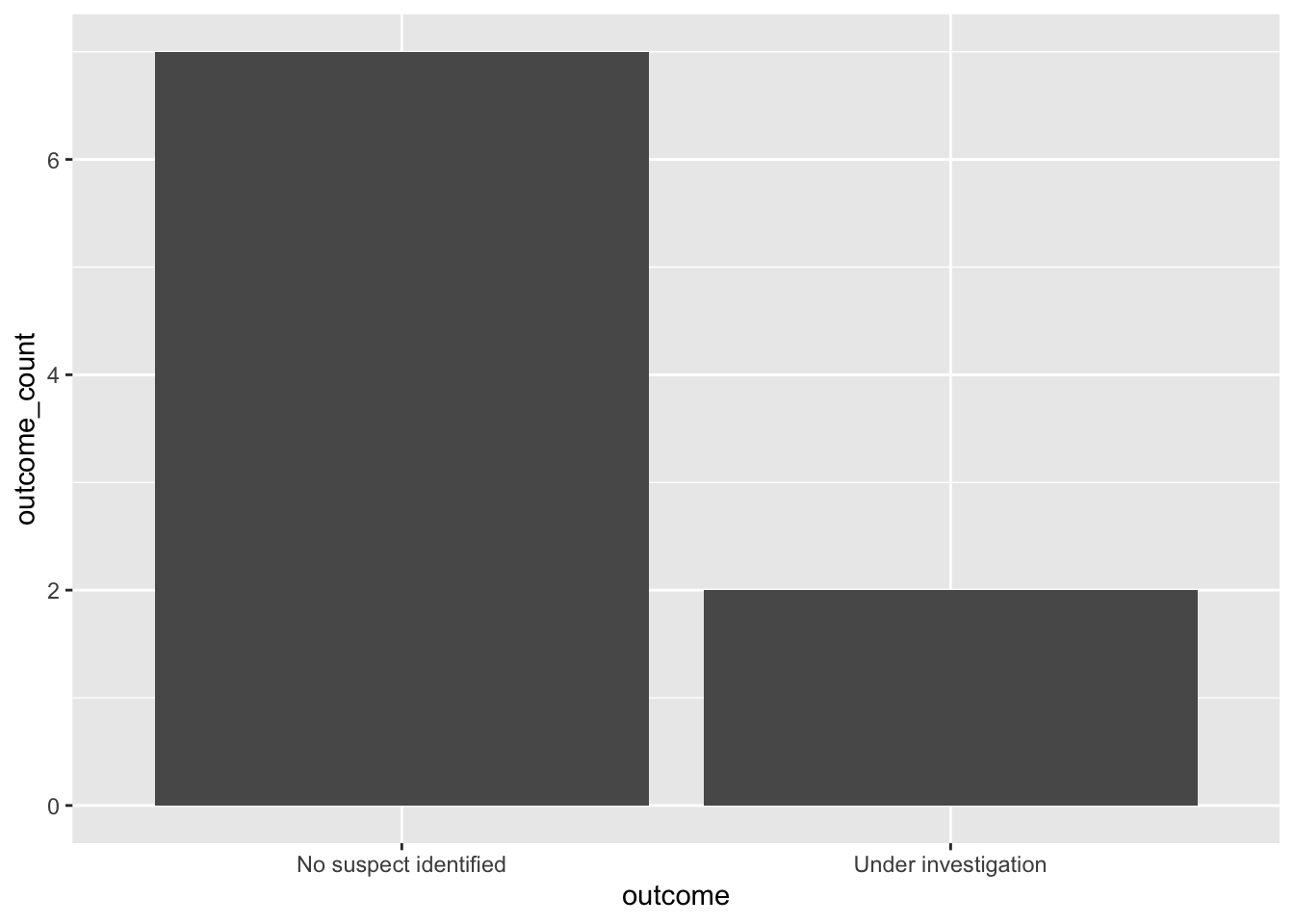
ggplot2 has loads of options to play with to make a better looking chart, but this will give you an idea and an introduction to it. We’ll look at this more in due course.
Conclusion
As well as importing files, it is possible to get data straight from a web server that allows it using an API - here we’ve built an API call, got JSON data back and turned it into a dataframe before going over the pivot table (group by function) and introducing a simple chart.